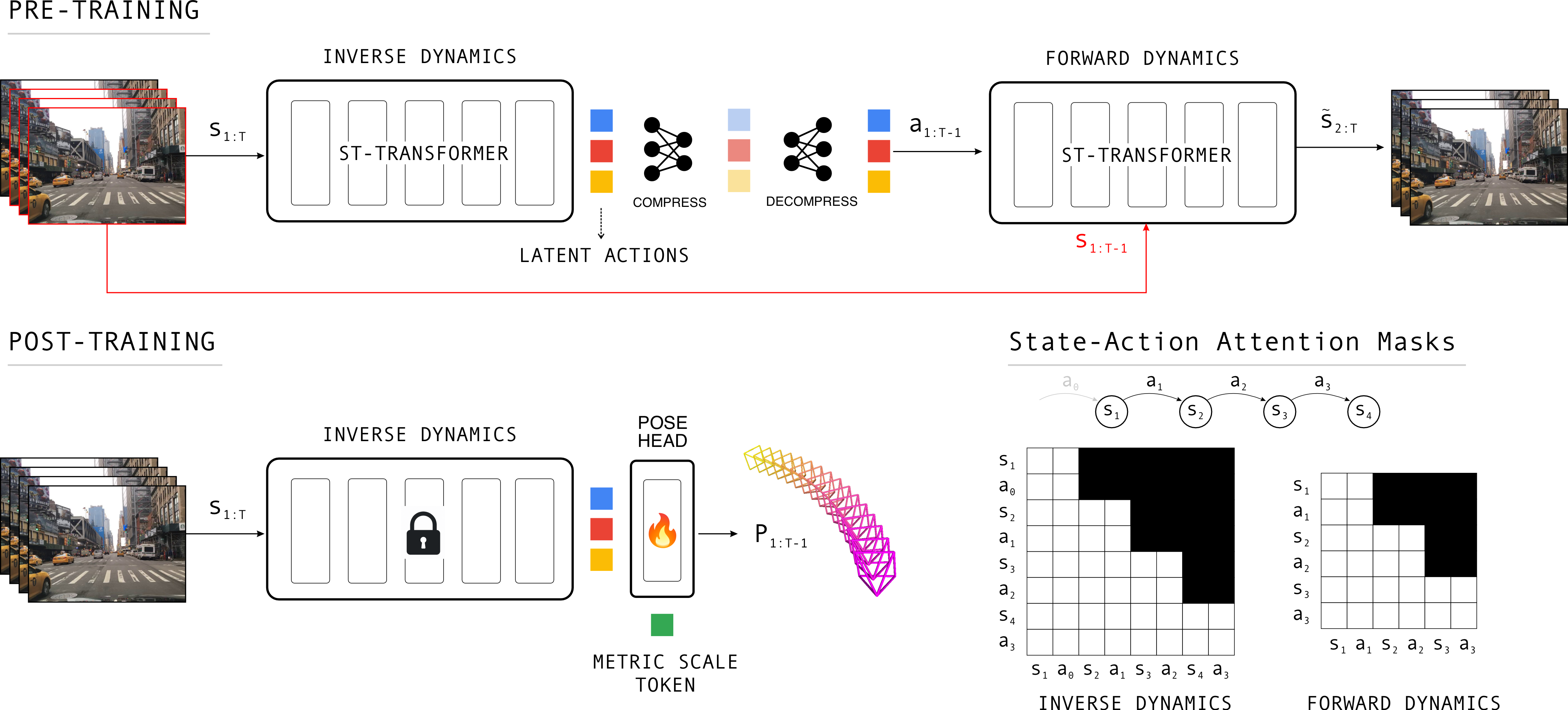
Method
Latent action pretraining, then pose post-training
The same motion representation learned from consecutive frames becomes the signal for metric camera pose prediction.
Latent Action Pretraining Meets Pose Estimation
A feed-forward pose estimator that converts self-supervised latent actions learned from large-scale driving video into accurate, generalizable camera motion.
Abstract
This paper revisits camera pose estimation through the lens of self-supervised pretraining, focusing on inverse dynamics pretraining as a scalable alternative to the current trend of fully supervised training with 3D annotations. Concretely, we employ inverse- and forward dynamics models to learn latent action representations, similar to Genie from large-scale driving videos. Our idea is simple yet effective. Existing methods use latent actions in their original capacity, that is, as "action" conditioning of world-models or as proxies of robot "action" parameters in policy networks. Our method, dubbed LA-Pose, repurposes the latent action features as inputs to a camera pose estimator, finetuned on a limited set of high quality 3D annotations. This formulation enables accurate and generalizable pose prediction while maintaining feed-forward efficiency. Extensive experiments on driving benchmarks show that LA-Pose achieves competitive and even superior performance to state-of-the-art methods while using orders of magnitude less labeled data. Concretely, on the Waymo and PandaSet benchmarks, LA-Pose achieves over 10% higher pose accuracy than recent feed-forward methods. To our knowledge, this work is the first to demonstrate the power of inverse-dynamics self-supervised learning for pose estimation.
Method
The same motion representation learned from consecutive frames becomes the signal for metric camera pose prediction.
Interactive Latent Space
Toggle the coloring, click points, or select a cluster to inspect the driving sequences behind the representation.

Benchmark Results
Side-by-side driving videos and predicted trajectories on two standard autonomous driving benchmarks.
Generalization
Qualitative trajectory predictions beyond the standard benchmarks, shown through official Wayve posts and uncurated YouTube driving videos.
Official LinkedIn embeds from the four-day launch series.
Predicted camera trajectories on uncurated scenes spanning night, traffic, mountain roads, rain, and tunnels, with videos sourced from the OpenDV-YouTube dataset.
Citation
@inproceedings{Wang2026LAPose,
author = {Wang, Zhengqing and Nair, Saurabh and Chidananda, Prajwal and Kachana, Pujith and Li, Samuel and Brown, Matthew and Furukawa, Yasutaka},
title = {LA-Pose: Latent Action Pretraining Meets Pose Estimation},
booktitle = {CVPR},
year = {2026},
}Acknowledgments
We thank Jaskaran Singh Sodhi and Saloni Puran Parekh for their help with data construction, and Anner De Jong for engineering support. We are grateful to Thomas Kollar and Gianluca Corrado for reviewing the paper and providing valuable feedback. We also thank Shreyas Rajesh and Soham Phade for their early contributions to the idea of Latent-Actions.